
データ分析では、「データをどう集め、どう読み、どう結論づけるか」が結果の質を大きく左右します。
特に 時系列データの扱い、標本誤差とバイアスの違い、因果を検証するための実験設計 は、データサイエンティスト検定™ リテラシーレベルにおいても、実務においても極めて重要なテーマです。
本記事では、以下を 1つの流れとして整理します。
- 時系列データの基本構造
- トレンド・周期性とその除去
- 自己相関・偏自己相関
- 見せかけの回帰
- 標本誤差と標準誤差
- サンプリングバイアス・選択バイアス
- 実験計画法・分散分析・直交表
目次
1. 時系列データとは何か
時系列データとは、「時間の経過に従って記録されたデータ」を指します。
代表例:
- 気温
- 株価
- 商品売上
- アクセス数
- 来客数
時系列データの最大の特徴は、観測値同士が時間的に依存している点です。
そのため、通常のデータ分析と異なり、「時間構造」を無視すると誤った結論につながりやすくなります。
2. 時系列分析の核心:トレンドと周期性
トレンドとは
トレンドとは、短期的な変動をならしたときに見える、データ全体の長期的な方向性です。
- 売上が年々増加している
- 株価が長期的に下落している
などが典型例です。
周期性(季節性)とは
周期性とは、一定の間隔で繰り返し現れる変動パターンです。
例:
- 曜日周期(週末に売上増)
- 年周期(夏にアイスが売れる)
- 月次周期(月末に支出増)
周期性は、四季・天候・社会制度・慣習など、外部要因によって生じることがほとんどです。
3. トレンド把握の基本手法:移動平均
移動平均とは、一定期間(窓)内の平均を連続して計算し、系列をなめらかにする手法です。
- 窓を小さくする → 短期変動が残る
- 窓を大きくする → 長期トレンドが見える
周期性を除去したい場合は、その周期に合わせた窓幅を選ぶのが基本です
(例:曜日周期なら7日移動平均)。
4. 周期性を無視すると何が起きるか
周期性を考慮せずに分析すると、
- 相関があるように見える
- 施策効果が過大評価される
- 誤った因果関係を主張してしまう
といった問題が起こります。
そのため、経済指標などでは 原数値 ではなく、
季節変動を除いた 季節調整値 が用いられるのが一般的です。
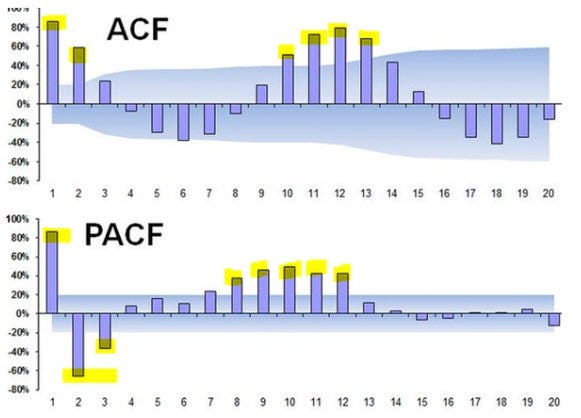
5. 周期を見つける:自己相関分析と偏自己相関分析
自己相関分析
自己相関分析は、時系列データが「自分自身の過去(ラグ)」とどの程度相関しているかを見る分析です。
- ラグ7で相関が強い → 週周期の可能性
- ラグ12で相関が強い → 月周期の可能性


偏自己相関分析
偏自己相関分析は、特定ラグ以外の影響を除いたうえで相関を見る方法です。
たとえば「t期とt-10期」の関係を見る際に、
t-1〜t-9の影響を取り除いて評価します。
これは、時系列モデル構築(ARモデルなど)で特に重要になります。

6. 見せかけの回帰という重大な落とし穴
時系列データ同士を回帰するとき、特に注意すべきなのが 見せかけの回帰 です。
何が起こるか
互いに無関係な ランダムウォーク 同士であっても、
- 回帰係数が有意
- 高い決定係数
が出てしまうことがあります。
これは、両系列がトレンド(非定常性)を持つためです。
主な対策
- ラグ変数を含めた回帰
- 差分をとった回帰
- 定常性を確認してから分析
時系列回帰では「まず疑う」が鉄則です。
7. 標本誤差とは何か
母集団から標本を無作為抽出すると、
取り出した標本によって推定結果は必ず変わります。
この推定値と母数との差を 標本誤差 と呼びます。
重要なポイントは、
無作為抽出をしても、標本誤差は必ず発生する
という点です。
8. 標準誤差とサンプルサイズ
母数は未知であるため、標本誤差そのものは計算できません。
そこで用いられるのが 標準誤差 です。
標準誤差は、
- 推定値のブレの大きさ
- 調査結果の信頼性
を表す統計量です。
一般に、
- サンプルサイズが大きいほど標準誤差は小さくなる
- 推定は安定する
という性質があります。
9. サンプリングバイアスと選択バイアス
サンプリングバイアス
サンプリングバイアスとは、不適切な抽出方法により、
母集団の特徴が反映されていない標本が得られることです。
例:
- 日本全体を知りたいのに、特定地域に偏った調査
⚠️ サンプルサイズを増やしても、同じ偏り方ならバイアスは解消されません。
選択バイアスの例
購買額が高い顧客にのみメルマガを送付し、その効果を分析すると、
- メルマガ効果
- もともとの購買意欲
が混ざってしまい、推定が歪みます。
これは 選択バイアス の典型例です。
10. 実験計画法とは何か
実験計画法は、1920年代にR.A.フィッシャーが体系化した統計手法です。
目的は、
- 少ない試行回数で
- 因子が結果に与える影響を
- 客観的に検証すること
品質管理、医療、マーケティング、広告最適化など、幅広く活用されています。
11. 分散分析(ANOVA)
分散分析は、
- 因子によるばらつき
- 実験誤差によるばらつき
を比較し、因子の影響が有意かどうかを検定する手法です。
- 一元配置:因子1つ
- 多元配置:因子2つ以上
があり、因子数が増えると実験回数が爆発的に増えます。
12. 直交表で実験回数を削減する
なぜ直交表が必要か
例:
- 背景色:2水準
- コピー:2水準
- 画像:2水準
→ 全組合せは 23=8 通り。
しかし L4(2³)直交表 を使えば、
- 任意の2因子の水準組合せが均等に出現
- 実験回数を 4回 に削減
できます。


交互作用を考慮しながら、最小回数で設計するのがポイントです。

