
本記事では、G検定で扱われる人工知能分野の基礎を、
「歴史 → 理論 → 技術 → 現代AI」 という流れで整理する。
個別技術の暗記ではなく、なぜその技術が生まれ、何が限界だったのかを重視する。
目次
1. 人工知能研究の歴史とAIブーム


4
第一次AIブーム:探索と推論の時代(1950年代〜)
人工知能研究は、
「人間の知的行動は論理と探索で表現できる」
という仮説から始まった。
この時代の中心技術は以下である。
- 状態空間探索
- 推論(論理・記号処理)
- ゲームAI(迷路、チェス、簡単なパズル)
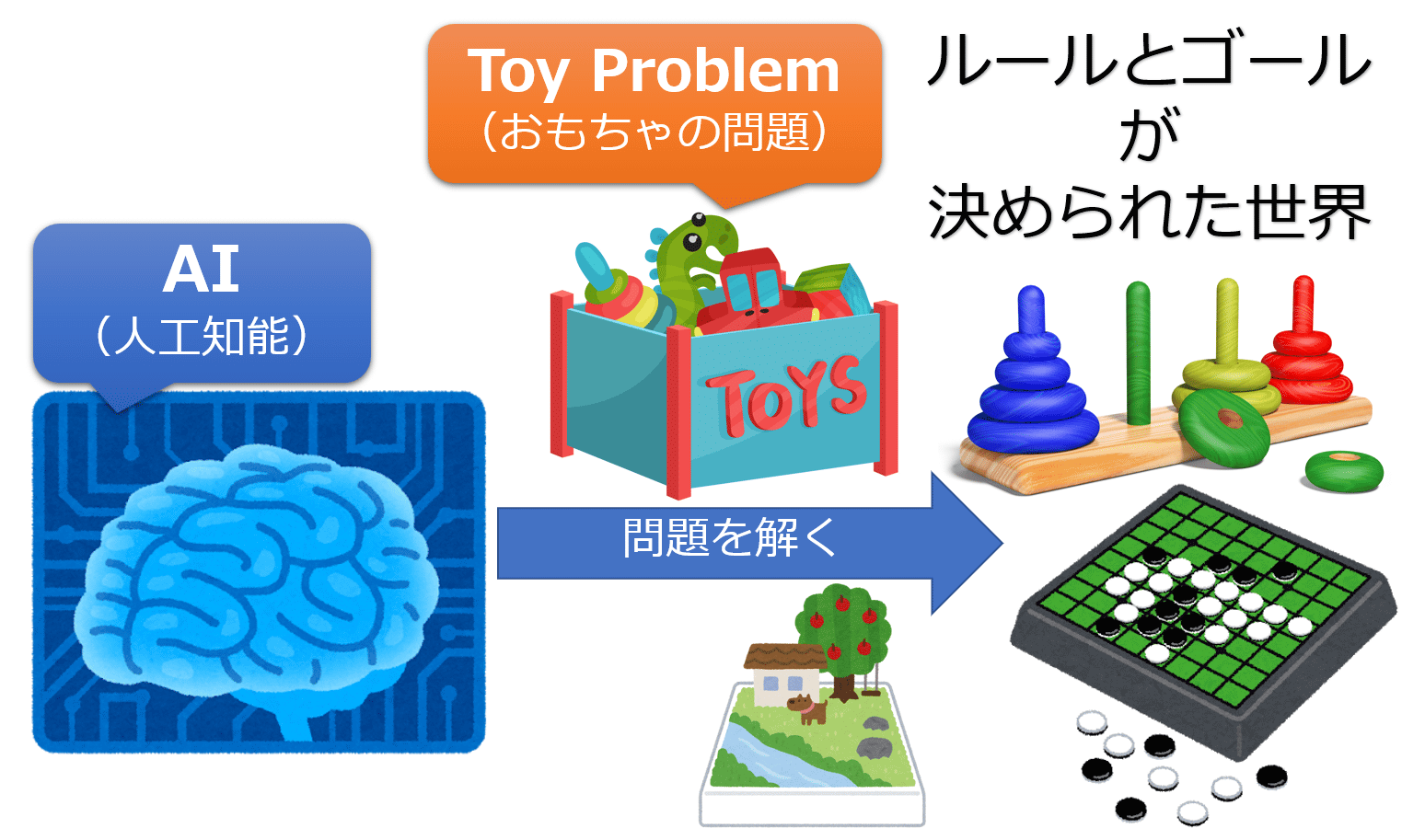
これらは一定の成功を収めたが、扱えた問題は
ルールが明確で、状態数が限定された問題に限られていた。
これらは後に トイ・プロブレム と呼ばれる。
現実世界のような
- ノイズが多い
- 状況が曖昧
- ルールが事前定義できない
問題には対応できず、第一次AIブームは終息する。
第二次AIブーム:知識と専門家の時代(1970〜80年代)
次に注目されたのが 「知識」 である。
- 専門家はどう判断しているのか
- その知識をルールとして表現できないか
この発想から エキスパートシステム が生まれた。
代表例:
- DENDRAL(化学構造推定)
- MYCIN(医療診断)
- ルールベース対話システム(イライザ)
しかしここで深刻な問題が生じる。
- 知識を人手で入力し続ける必要がある
- 知識の更新・保守コストが極めて高い
これを 知識獲得のボトルネック と呼ぶ。
結果として、第二次AIブームも失速する。
第三次AIブーム:学習するAI(2010年代〜)
現在のAIブームを支えているのは以下の3点である。
- ビッグデータ
- GPUなどの計算資源
- ディープラーニング
特に ImageNet(ILSVRC) において
2012年に登場した AlexNet が圧倒的性能を示したことが転機となった。
以降、画像・音声・自然言語の分野で
人手設計を超える性能 が次々に実現される。
2. 探索アルゴリズムとゲームAI
探索とは、
「状態の集合から目的状態へ到達する経路を見つけること」
である。
幅優先探索(Breadth First Search)
- スタートに近い状態から順に探索
- 最短経路を必ず発見できる
- ただしメモリ消費が非常に大きい
迷路やグラフ探索の基本手法として重要。
Mini-Max法と完全情報ゲーム
チェスやオセロのようなゲームでは、
- 自分は最善手を選ぶ
- 相手も必ず最善手を選ぶ
と仮定して探索を行う。
これを Mini-Max法 と呼ぶ。
- 自分のターン:スコア最大化
- 相手のターン:スコア最小化
計算量削減のために導入されるのが αβ法 であり、
本質的には Mini-Max法の枝刈り手法である。
モンテカルロ法とMCTS
現代のゲームAI(囲碁・将棋)で重要なのが モンテカルロ法。
- 仮想的なプレイアウトを多数回実行
- 勝率などの統計量で局面を評価
- 明示的な評価関数が不要
これにより、
評価が困難な複雑ゲームでも高性能なAIが実現した。
3. ロボットとプランニング技術
プランニングとは何か
プランニングとは、
目標を達成するための行動列を論理的に計画する技術
である。
- 現在の状態
- 可能な行動
- 行動後の状態
を記号として扱う。
SHRDLU と STRIPS
代表的なプランニングAI:
- SHRDLU
- ブロック世界での自然言語理解と行動計画
- STRIPS
- 行動前後の状態変化を論理式で定義
これらは後のロボット制御や自動計画の基礎となった。
4. 知識表現・意味ネットワーク・オントロジー



意味ネットワーク
知識を 概念ノードと関係 で表現する方法。
特に重要なのが is-a 関係。
例:
- 犬 is-a 動物
- 動物 is-a 生物
これにより性質の 継承 が可能となる。
セマンティックウェブとLOD
セマンティックウェブとは、
Web上の情報に意味を付与し、
コンピュータが理解・推論できるようにする構想
関連技術:
- RDF
- オントロジー
- LOD(Linked Open Data)
単なるデータ収集(ウェブマイニング)とは目的が異なる。
5. Question Answering と Watson


IBMが開発した Watson は
Question Answering 技術の代表例である。
特徴:
- 自然言語の質問を解析
- 大量の文書から根拠を抽出
- 確率的に最適な回答を提示
クイズ番組 Jeopardy! で人間に勝利したことで注目された。
ただし、
- 人間のような理解や意識を持つわけではない
- 自律的に知識体系を構築するわけでもない
点には注意が必要である。
6. 機械学習とディープラーニングの本質
ルールベース vs 機械学習
| 観点 | ルールベース | 機械学習 |
|---|---|---|
| 特徴量 | 人手設計 | 学習で獲得 |
| 柔軟性 | 低い | 高い |
| 保守 | 困難 | 比較的容易 |
機械学習は
データからパターンを学ぶ ことが本質。
ディープラーニングの革新性
従来の機械学習:
- 特徴抽出:人間
- 学習:モデル
ディープラーニング:
- 特徴抽出そのものを学習
多層ニューラルネットワークは
人間の脳神経回路を抽象化した構造を持つ。
これにより、
- 画像
- 音声
- 言語
といった非構造データを直接扱えるようになった。
まとめ:G検定で重要なのは「流れ」と「限界」
この分野で本当に重要なのは、
- 技術名の暗記
- モデル名の羅列
ではない。
- なぜその技術が生まれたのか
- なぜ限界に直面したのか
- 何がブレイクスルーだったのか
この 流れの理解 こそが、
G検定・実務・AIリテラシーすべての基盤になる。

