統計分析において「ロバスト性」という概念は、データの分布や外れ値の影響を受けにくい手法の特性を指します。本記事では、統計的ロバスト性の基本的な定義から、その重要性、具体的な手法、実際の応用例までを分かりやすく解説します。
統計的なロバスト性とは?
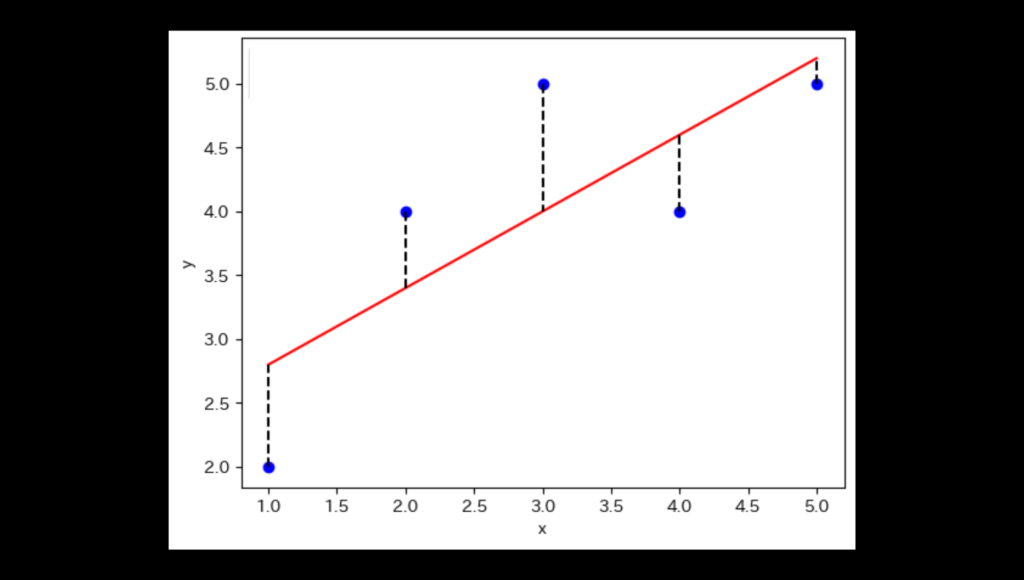
ロバスト性(robustness)は、統計手法やモデルが理想的な仮定が崩れた場合でも、性能を大きく損なわない性質を指します。例えば、正規分布を仮定した手法が外れ値や分布の歪みに対して敏感でない場合、それはロバスト性が高いといえます。
ロバスト性の重要性
現実のデータは、必ずしも理論通りに従うわけではありません。外れ値や分布の歪み、データ不足などの要因がある中で、信頼できる分析結果を得るためには、ロバスト性の高い統計手法が必要です。
ロバスト性の高い手法の例
1. 中央値(Median)
平均値は外れ値の影響を受けやすいですが、中央値はその影響を受けにくいため、ロバストな位置の指標としてよく使われます。
2. マン・ホイットニーのU検定
これは、非パラメトリックな検定手法であり、分布の形状に対してロバスト性が高いです。
3. Huber損失関数
線形回帰や機械学習の分野で用いられるHuber損失は、外れ値の影響を軽減することでロバスト性を向上させます。
ロバスト性を考慮する場面
データに外れ値が含まれる場合
外れ値が分析結果に与える影響を最小限に抑えるために、ロバストな手法を使用します。
分布の仮定が満たされない場合
例えば、正規分布を仮定したt検定の代わりに、ロバスト性の高いランク検定を使用することがあります。
ロバスト性の応用例
医療分野
患者データは外れ値が含まれることが多いため、ロバストなモデルが必要です。例えば、ロバスト回帰を使用して治療効果を分析することがあります。
金融分野
市場データは変動が激しく外れ値も多いため、ロバスト性の高いポートフォリオ最適化手法が重要です。
機械学習
ノイズや外れ値が多いデータセットに対して、ロバストな学習アルゴリズムが必要とされます。
ロバスト性と他の統計概念との関係
バイアス・バリアンスのトレードオフ
ロバスト性を高めることでバイアスが増えることがありますが、バリアンスの低減や予測精度の向上が期待できます。
モデルの頑健性(Model Robustness)
ロバスト性は、モデル全体の頑健性とも関連します。頑健性の高いモデルは、データの変動やノイズに対しても安定した結果を出します。
まとめ
統計的なロバスト性は、現実のデータ分析において極めて重要な要素です。外れ値や分布の仮定が崩れる状況でも信頼できる結果を得るために、ロバスト性の高い手法やモデルを選択することが求められます。医療や金融、機械学習など多くの分野で応用されるロバスト性について理解を深め、実際の分析に役立ててください。
統計的ロバスト性に関するさらなるご質問があれば、ぜひコメントでお知らせください!
データ分析のキャリアを目指すあなたへ!
統計学や機械学習は、データサイエンスやAIエンジニアリングの基盤となる分野です。
こうした知識を深め、実践的なスキルを身につければ、需要の高いAI関連職種でのキャリア形成も目指せます。
未経験からでも安心して学べるおすすめのキャリア支援サービスについて、こちらの記事で詳しく解説していますので、ぜひチェックしてみてください。